
Data Availability
Sequencing data will be deposited at NCBI under the umbrella BioProject PRJNA1336838. Data generation is currently in the early stages - please check back for updates as datasets become available.
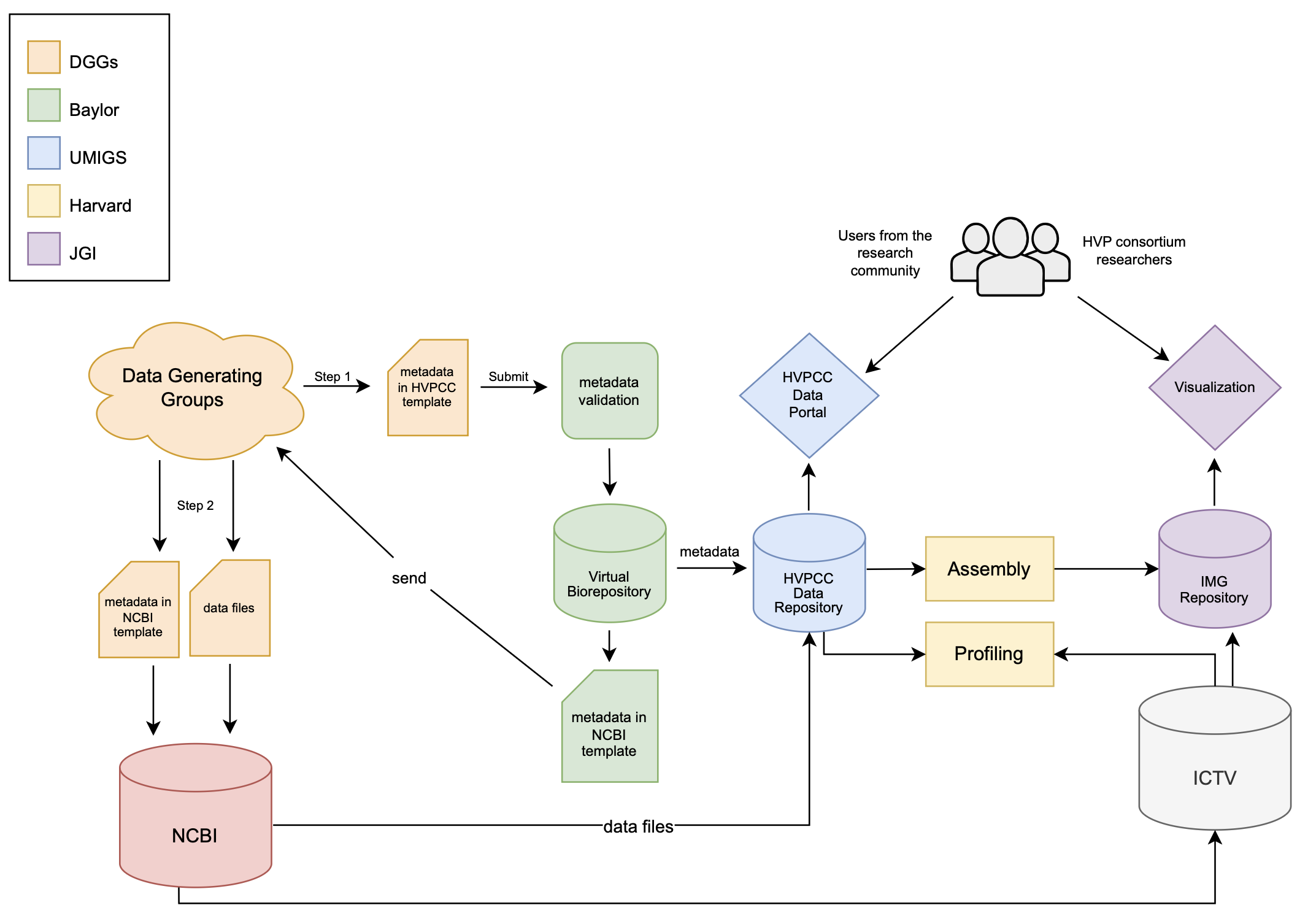
Data Flow
The diagram below outlines the Human Virome Program data flow from the data generating groups through data deposition, analysis and visualization. The Virtual Biorepository (VBR) at Baylor will be the first entry point for metadata from the data generating groups into the Data Coordination Center. The VBR will validate the metadata and provide the data generators with formatted templates for them to use when submitting their data to NCBI. Once the metadata is validated, the Data Repository group at the University of Maryland School of Medicine will pull the metadata from the VBR and the data files from NCBI.
The metadata will be used to power the HVP Data Portal, a web-based tool that provides users with the ability to search for HVP primary and derived data files of interest based on the metadata. Centralized consistent processing of the primary data will be carried out at Harvard and that information will be sent to the Integrated Microbial Genomes repository at the Joint Genomes Institute where users can access all the tools of that resource to visualize and explore the data.
Metadata Dictionary
A comprehensive and harmonized metadata framework for participants, samples,libraries, files, and data analyses across all Human Virome Program projects was developed through the work of the HVP Metadata Working Group. All 15 funded groups within the HVP were invited to participate in and sign-off on the metadata fields, their definitions, and how the values for each field would be captured. This resulted in five data dictionaries and associated templates that data generators will use to submit metadata to the Virtual Biorepository within the HVP Coordination Center.